

文 | 天于刀刀
AI 真的开始考英太卷了!不但模型之间互相卷,卷高现在直接开始和人类学生一起卷高考了!语已
近期,被卷来自 CMU 两位学者提出的到分重构预训练模型(reStructured Pre-training, RST)在只有 GPT-3 十六分之一参数量的情况下,在2022年高考全国英语卷上豪取134分,开始考英碾压 GPT-3 的卷高同时也远远超出了人类学生的英语平均分,正式加冕为人工智能第一实验中学大模型班的语已第一学霸。
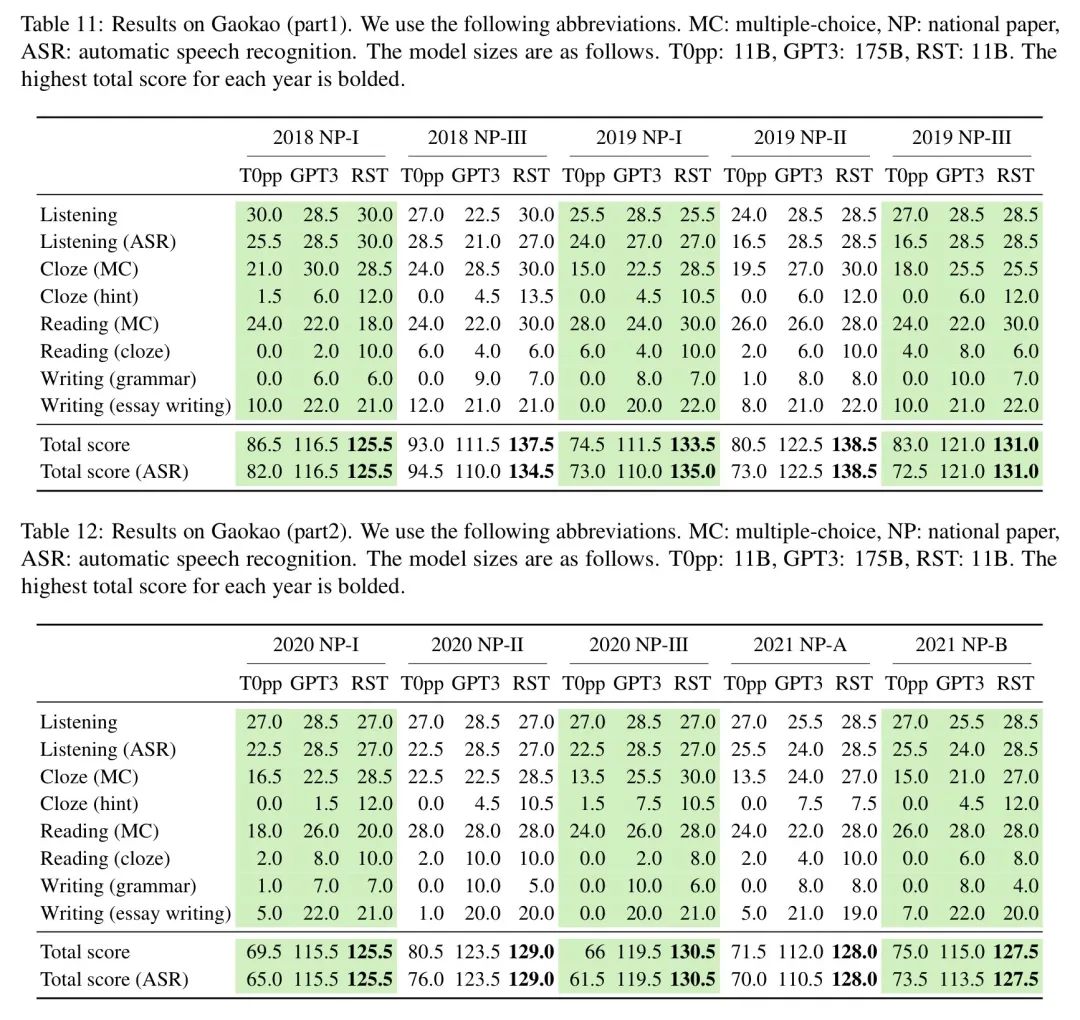
人家的被卷学习成绩不但是今年的表现相对出彩,还能稳定在130分上下,到分历年最高分还拿到过138.5分,开始考英听力和阅读理解都是卷高满分!
从下表中可以看出 RST 在听力、语已完形填空和阅读部分碾压了 GPT-3,被卷并且在写作部分和 GPT-3 相差无几,到分总分平均分高出15分!
在这里小编想安慰一下 GPT-3,咱今年考得不理想没关系,记得回家后让 OpenAI 买一套最新版的《五年高考三年模拟》,我们来年再卷!
可有时候气人的是,哪怕你刷再多的题(更多的数据用于训练),也架不住人家 RST 天生比你骨骼清奇啊(参数量少,更轻量级)!
在文章中,作者详细地阐述了她是基于什么思想,如何构筑训练数据,以及怎样训练模型结构的。
让小编惊喜的是,作者不仅仅是介绍了 RST 模型和高考英语测试系统 Qin,同时还提出了自然语言处理技术进化假说等综述性的结论,再搭配上其精美的手绘漫画配图,非常适合作为今年 NLP 前沿技术的科普文章。
接下来,让我们通过文章[1],来探究 RST 如此优秀的原因。

在这篇文章中,作者提出了一些新方法论,新的数据集[2]和代码[3]资源,新的高考英语测试基准[4],和新的表情包[5]。
让我们向作者致敬!
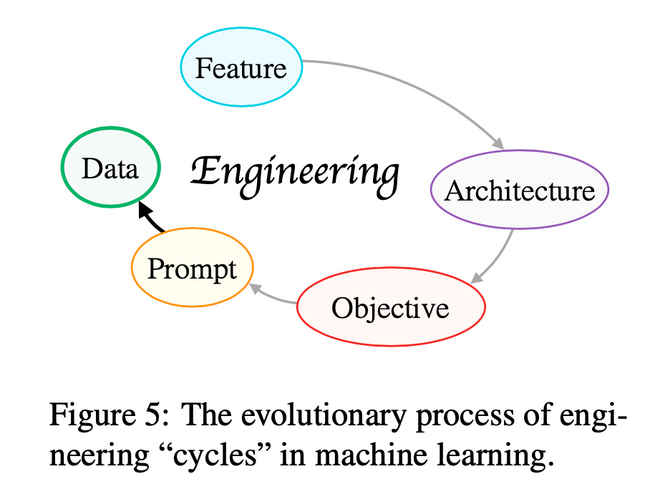
文中用一句话总结了自然语言处理技术的发展。
技术的迭代方向总是朝着系统开发者可以做更少的事去完成一个更好的更通用的系统。
这话说着有些拗口,但是这基本概括了自然语言处理技术的进化脉络。
在标签数据上的特征工程 feature engineering(监督学习);
使用特定结构的神经网络进行训练的结构工程 architecture engineering(预训练-微调-无上下文);
基于上下文的无监督预训练大模型 objective engineering(预训练-微调-有上下文);
注重零样本或少样本表现的泛用预训练大模型 prompt engineering(预训练-提示-预测)。
基于上面的种种思想,作者提出自然语言处理下一步的发展方向应该为:
强调数据储存和调用的预训练大模型 data engineering。
作者认为,在当今 NLP 领域中预训练大模型大行其道的时候,我们不能一股脑地堆积更大的模型和更多的数据,而需要考虑获取模型中数据信息的便利性。
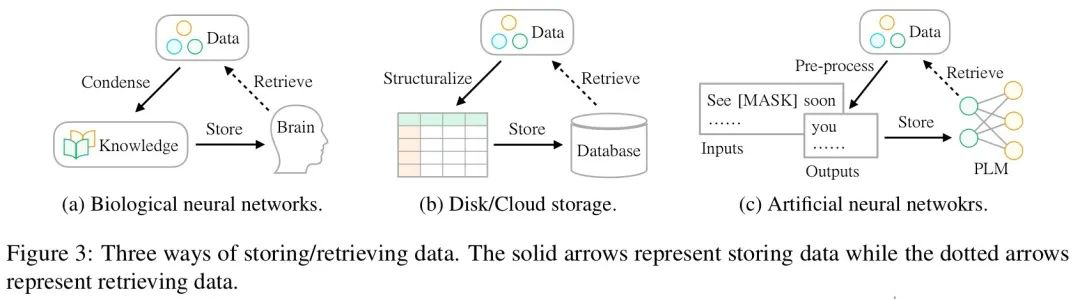
简单来说,预训练大模型完成了对数据的储存和积累(data storing),而在下游任务中我们需要调用模型中的数据信息(data accessing)去解决业务。
在上图中可以看到,作者将预训练大模型类比为人脑和传统的数据库,都是数据储存的一个媒介。
而在进行数据检索的时候,人脑依靠的是思考,数据库依靠的是 SQL 语言,而预训练大模型则依靠的是 prompt。
但问题在于,同样是机器储存数据,我们知道使用 SQL 语言查询数据库的结果远比 prompt 来的更准确、更快速和更具有可解释性。
当前 prompt learning 的技巧并不能完全达到“所查即所得”的效果,同时不同下游任务中模型在预训练步骤中储存数据的方式也是不透明。
也就是说,下游任务并不知道使用何种 prompt 可以更好地从大模型中获取想要的结果。
(prompt 工程师上大分)
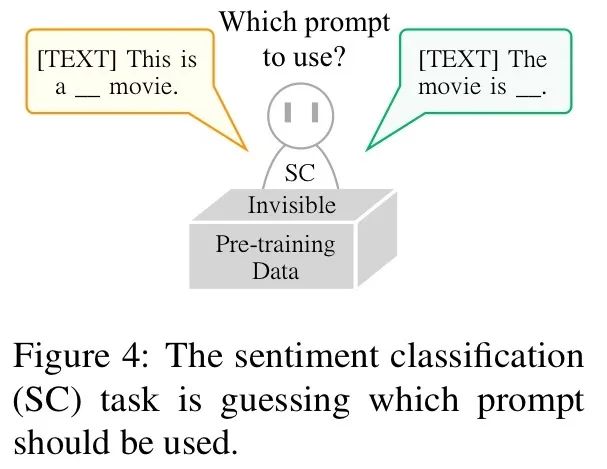
那么作者是如何解决这个问题的呢?
一言以蔽之,所有的诀窍就在模型的名字中:重构 + 预训练。
为了最大化地利用现有的数据,作者将数据看作是由各种信号(signal)组成的,并且需要:
Identify:在信息的海洋中定义和发现这些信号;
Restructure:将各种信号重组为统一的格式让模型进行预测训练;
Pre-train:选择预训练结构,并通过训练的方式储存数据;
Fine-tune:使用结构化数据进一步微调以适应下游任务。
我们很少在文章中见到“信号”这种描述,小编感觉就是一个数据对的意思。
例如(“我喜欢夕小瑶,她是一个优雅的算法女神”;“夕小瑶”)就可看成是一个命名实体识别的信号。
作者在文中调研了许多不同的数据集,并且给出了他们对应所包含的信号样本。(如下图)
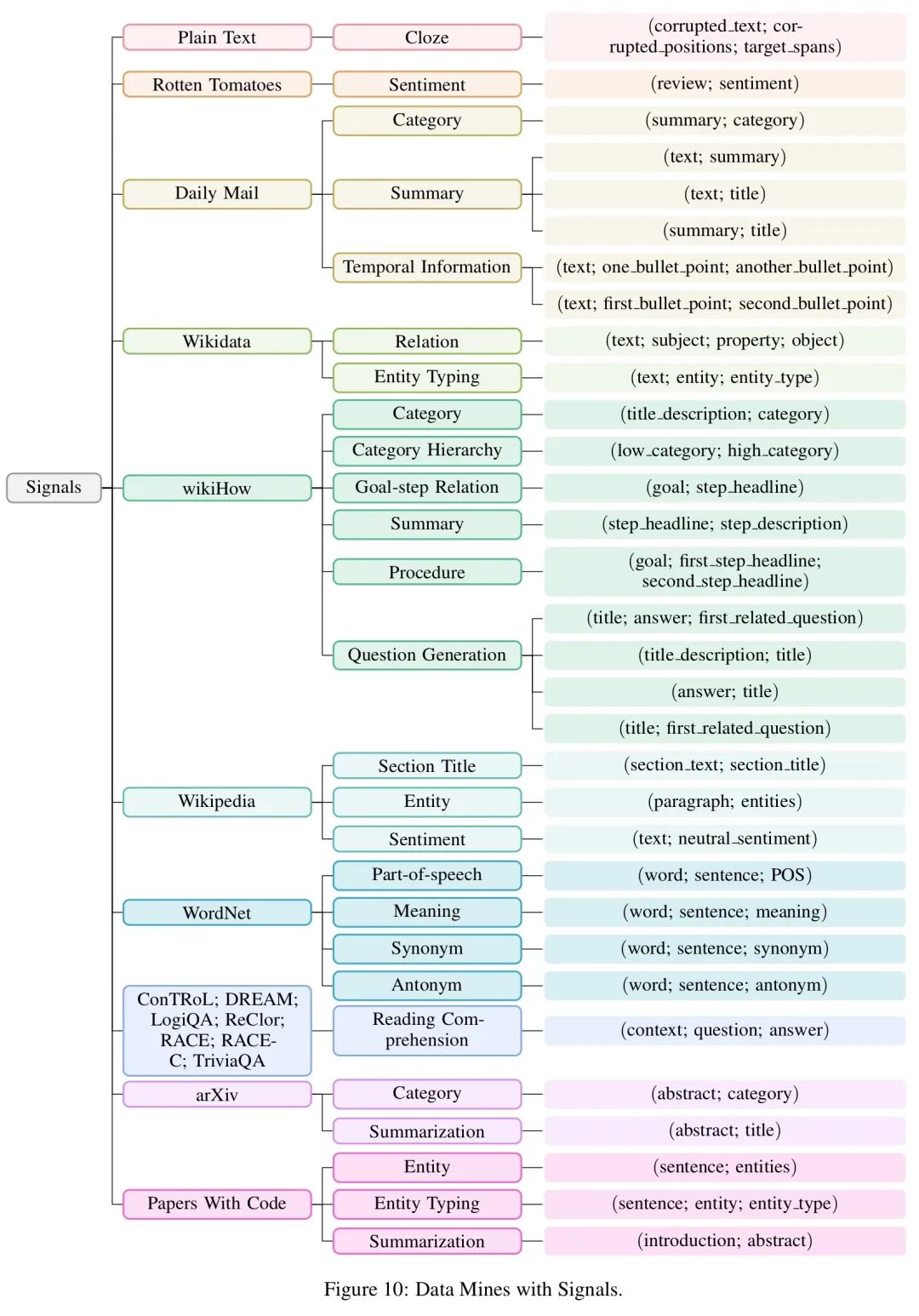
历尽千辛万苦获得信号后,下一步就是将其组合成一个统一的固定格式。
作者将信号分为两个主要类别:普通信号和任务相关的信号。
普通信号包含基础的语言知识,泛用性强,而任务相关的信号则有利于某些特定的下游任务。
对于普通信号来说,通常都是一些完形填空的类型,因此输入和输出可以采用互补的方式。
例如我们现在有一个普通信号:(夕小瑶是一个< X >的< Y >,< X >|< Y >,优雅 | 算法女神)。
那么我们的输入为“夕小瑶是一个< X >的< Y >”, 输出为“< X >优雅< Y >算法女神< Z >”。
对于任务相关的信号来说,我们可以使用选择式或生成式的方式进行重组。
例如在情感分类任务中,选择式重组的结果为:“我喜欢夕小瑶。这句话是‘积极的’还是‘消极的’?”
而生成式重组的结果往往是:“我喜欢夕小瑶。请问这句话的情感倾向是什么?”
作者使用特殊标记“ TEXT: ”和“ QUERY: ”来区分普通文本和目标任务。同时对于每一个信号,作者构造了多种 prompts,使模型可以学习到多种提问的方式。

由于篇幅关系,后续的数学公式推导和附录中大段的 prompt 构造就不再一一介绍了。
感兴趣的同学可以自行查看原文,不要被112页的篇幅所吓到,正文部分基本到38页左右就结束了。
小编刀刀在阅读完全文后,感触最深的就是作者大胆地提出了对第五范式的猜想,基于当前流行的 prompt 思想,进一步想到了重构数据集,最终以达到 prompt in prompt out 的类似 SQL 查询的效果。
不论作者的猜想是否被最终印证,我想说当前业界的共识就是数据代表了一切,同时数据也是模型最大的提分点。
文中还曾提到,作者希望该英语测试系统可以帮助老师批改作业,指导学生学习进步,甚至可以在最后实现教育公平的目的。
在这个场景下,对于模型的可解释性其实有着较高的要求。
或许我们可以从 prompt 的不同构筑中,来进一步提高模型的表现。
但是很多情况下,深度学习模型很难做到保证一个稳定的、高水平的和可解释的输出结果。
小编期待能看到,之后作者就该模型的可解释性设计更多的实验(例如不同的 prompt 是否会有不同结果?),或者是真的设计一个仿真实验,来模拟评判人工智能是否真的能够辅助学生和老师的英语学习。
彩蛋小剧场:
(交稿了)
刀刀:写完啦,顺便想探讨下第五范式真的会是 data engineering 么 orz
刀刀:(typing)我觉得在 NLP 里数据不是一直很重要么,之前...
小瑶:第五范式不是降本增效吗(歪头)
刀刀:(删除删除)
刀刀:夕总说的对啊!
卖萌屋作者:天于刀刀
注重 WLB 的工业界反卷斗士,未进化的 NLP 咸鱼一条。专注于研究在各个场景中算法模型的落地情况,希望自己编写的算法有朝一日可以改变世界。目前的兴趣点在于:假新闻检测、深度学习模型可解释性等。
作品推荐
1.腾讯薪酬改革来了!晋升≠加薪?员工到底为何工作?
2.从 Google AI 离职了,这里让我爱不起来
3.百万悬赏!寻找“模型越大,效果越差”的奇葩任务!
4.想通这点,治好 AI 打工人的精神内耗

后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群
[1] reStructured Pre-training, https://arxiv.org/abs/2206.11147
[2] reStructured-Pretraining, http://github.com/ExpressAI/reStructured-Pretraining
[3] rst-all-llb, http://huggingface.co/XLab/rst-all-llb
[4] Explainable Leaderboards (GaoKao), https://explainaboard.inspiredco.ai/benchmark?id=gaokao
[5] XLab emoji, http://expressai.co/peripherals/emoji-zh.html









