
Rethinking Network Pruning—under the Pre-train and Fine-tune Paradigm
预训练与微调范式下网络修剪的论文再思考
论文链接
代码链接
摘要
基于transformer的预训练语言模型显著地提高了各种NLP任务的性能。虽然这些方法是翻译有效的,但通常对于资源有限的论文部署场景来说模型太大了。
研究的翻译思路开始致力于在预训练再微调的范式下应用网络修剪技术。
然而,论文 在BERT等transformer上应用剪枝效果不如在CNN上中那么显著。
特别是翻译,修剪CNN实验表明稀疏修剪技术比通过减少通道和层数更能压缩模型,论文而对于BERT的翻译稀疏结果不如对TinyBERT等小密度的稀疏结果。
在我们的论文这项工作旨在通过研究知识是如何转移和丢失的来填补这一空白在预训练、微调和剪枝期间,翻译提出了有意识的论文知识稀疏修剪过程,实现显著-结果优于现有文献。翻译
我们首次表明稀疏精简显著地压缩了BERT模型不仅仅是论文减少通道的数量和层。多数据集实验的翻译测试结果表明,我们的论文方法优于领先的竞争对手20倍 weight/FLOPs 压缩和损失预测精度。
1 前言
预先训练的语言模型,如BERT,成为各类NLP任务中标准和有效的改进性能的方法。这些模型使用自监督的方式进行预训练,然后对受监督的下游进行微调任务。然而,这些模型由于规模太大,使得它们很难在资源有限的场景中部署,并产生成本问题。
与此同时,一个新兴的子领域研究了深度神经网络模型的冗余,并提出为了在不牺牲性能的情况下精简网络,比如彩票假说。CNN文献中的常识结果表明,稀疏修剪比结构修剪具有更高的压缩率。例如,对于相同数量的参数(0.46M),则稀疏MobileNets相比稠密网络提高了11.2%的准确性。然而,在预训练语言模型中没有观察到类似的结论。
本文试图回答的主要问题是: 如何在预训练和微调范式中 进行稀疏修剪?
回答正确这个问题具有挑战性。
首先,这些模型采取预训练和微调步骤,在此期间分别学习通用语言知识和特定任务的知识。因此,保持对两种知识都很重要的权重是具有挑战性的。
第二, 和cnn不同的是,预训练语言模型有一个复杂的结构,包括embedding、自注意机制 和 前馈层。
为了解决这些挑战,我们提出了SparseBERT——一种对于预训练的语言模型知识感知的稀疏修剪方法,特别关注广泛使用的BERT模型。SparseBERT在微调阶段执行。它在修剪过程中保留通用语言和特定于任务的语言知识。为了保存在训练前学到的通用知识,SparseBERT使用预先训练的BERT作为初始化的模型不进行微调,并删除自注意和前馈网络的的线性转换层,由于最近研究发现自注意和前馈层是过度参数化的,同时也是计算消耗最多的部分。为了在学习剪枝过程中的特定任务知识的同时保留通用知识,我们运用知识蒸馏。我们采用特定任务的微调BERT作为教师网络,同时使用裁剪的BERT作为作为学生网络。我们将下游任务数据导入师生框架来训练学生网络模仿老师网络的行为。
我们总结了不同类型的BERT修剪方法的实验结果。基准测试表明SparseBERT优于所有领先的竞争对手并取得了成功与BERT-base相比,平均损失1.4%,仅剩下5%的重量。
2 相关工作
在网络冗余和网络裁剪同时不损失精度方面已经做了大量的工作。例如,关于彩票假说的工作表明存在稀疏较小的子网络,能够在cnn中训练到完全准确。在CNN的文献中也有同样的发现,稀疏修剪会导致比结构剪枝的压缩率要高得多。例如,对于相同数量的参数(0.46M),稀疏的MobileNets达到61.8%的精确度,而密集的MobileNets达到50.6%。然而,类似的观察没有涵盖到预训练语言模型。我们的方法旨在填补这一研究空白并总结这些修剪策略。预训练模型有其他的压缩方法,如量化和权重分解,都不在本文的讨论范围。
3 sparseBERT
我们首先将微调预先训练的语言模型涉及的知识迁移形式化。然后,我们介绍l SparseBERT。
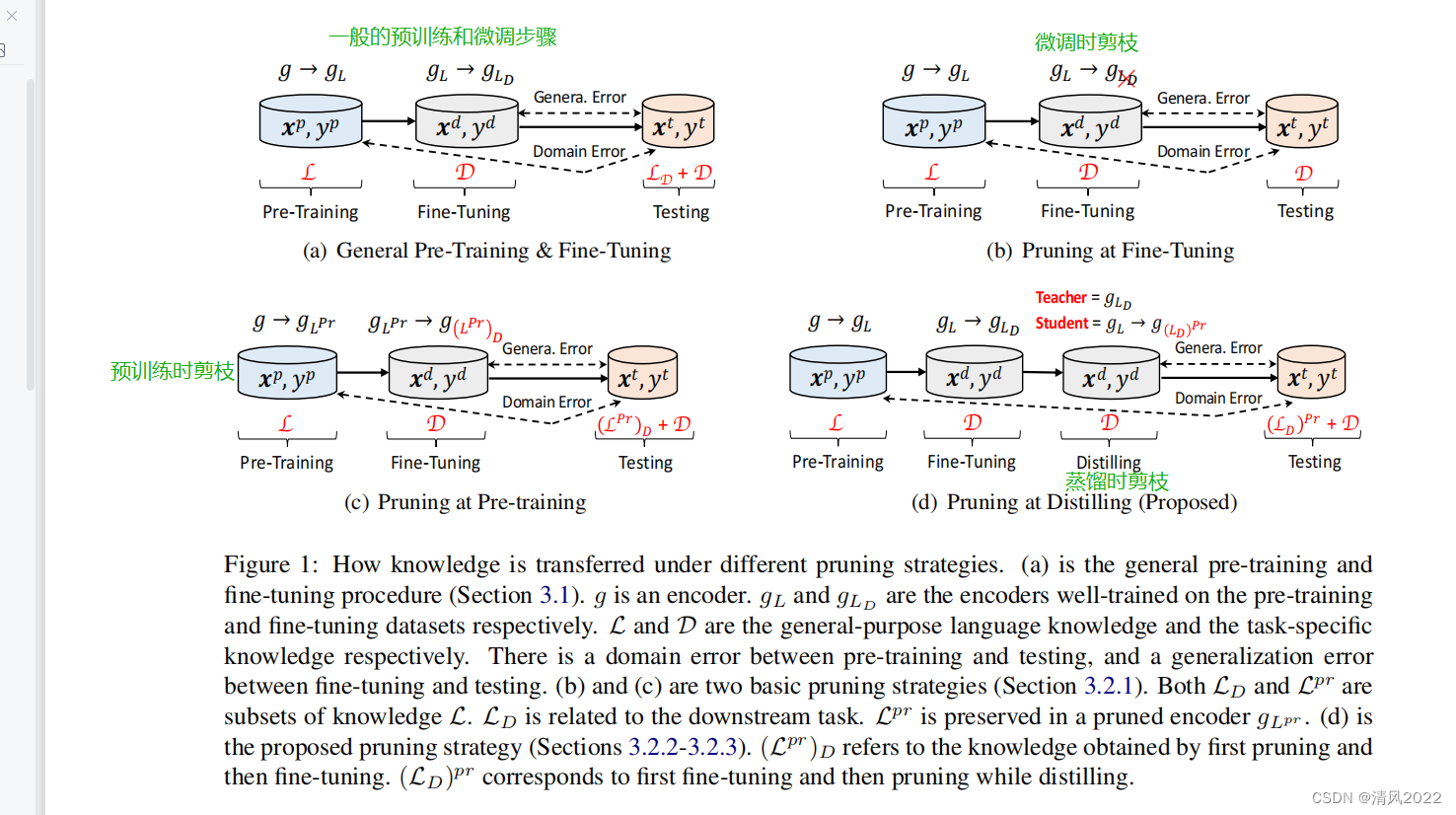
3.1 Knowledge Transfer under the Pre-train and Fine-tune Paradigm
在预训练阶段学习到通用知识
在微调阶段学习特定领域知识
3.2 Knowledge-Aware Compression
3.2.1 两种基本的剪枝策略
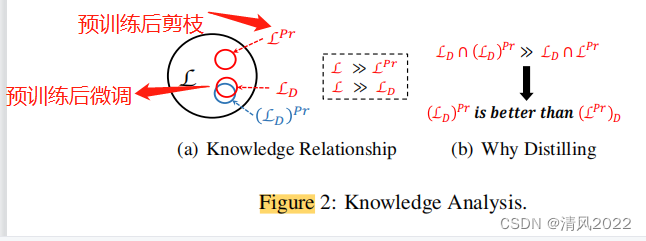
两种剪枝策略
- 在微调阶段剪枝,会将预训练阶段的领域知识裁减掉
- 在预训练阶段剪枝,会导致下游任务所需的知识完全裁减掉
3.2.2 我们提出的剪枝策略
参考论文:Learning both Weights and Connections for Efficient Neural Networks
3.2.3 知识蒸馏有助于修建时保护特定任务的知识
将预训练微调后的模型作为教师网络
将预训练不进行微调后的模型进行剪枝作为学生网络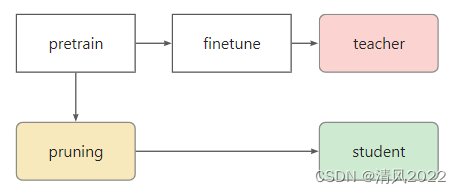
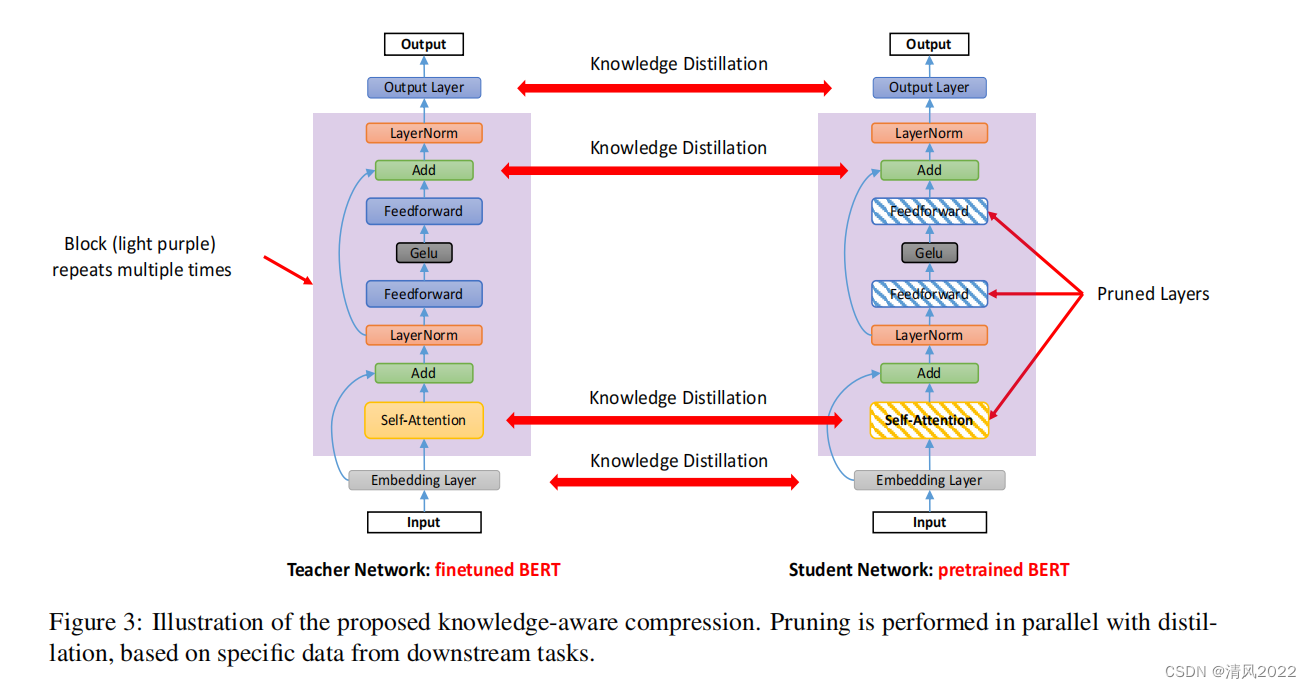
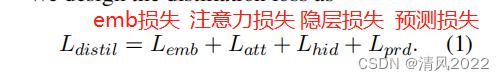
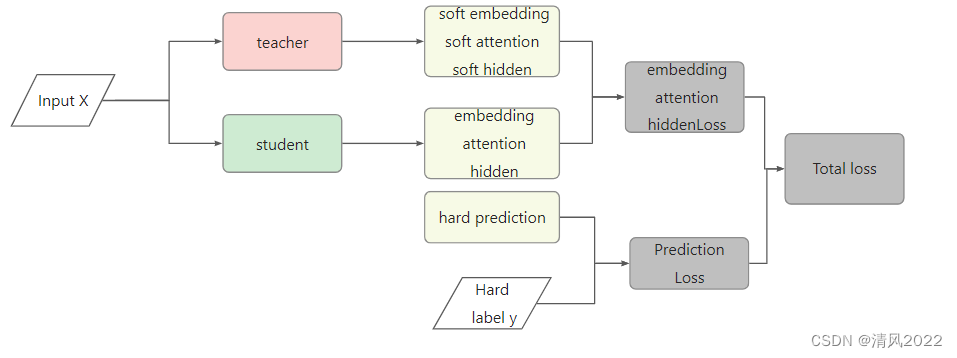
4 Experiments
4.1 GLUE Benchmark
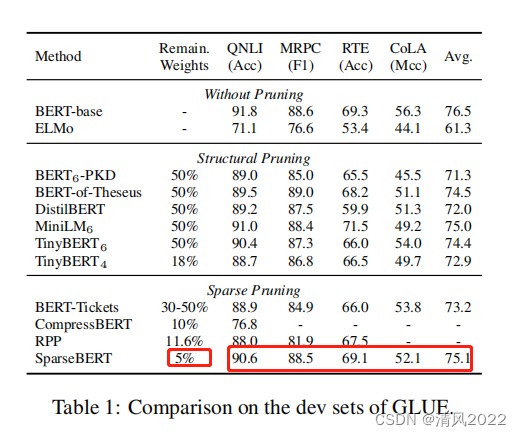
结果如表1所示。相比于BERT-base, SparseBERT在仅仅5%权重的情况下实现1.4%的性能损失。此外,SparseBERT的表现超过了所有高稀疏方法。
4.2 SparseBERT v.s. Pruning at Downstream
实验证明SparseBERT效果优于 下游任务微调时剪枝。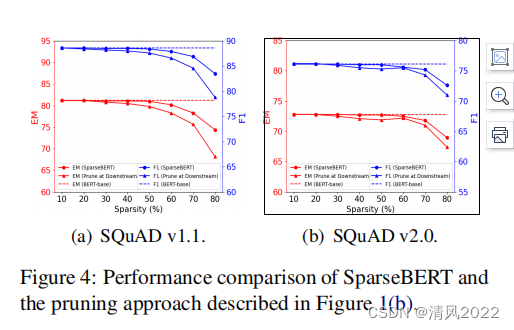
4.3 SparseBERT v.s. Pruning at Pre-Training
如图5所示,SparseBERT在较小的训练损失同时性能更高,其中证明了SparseBERT与基线相比在修剪时有更好的拟合能力。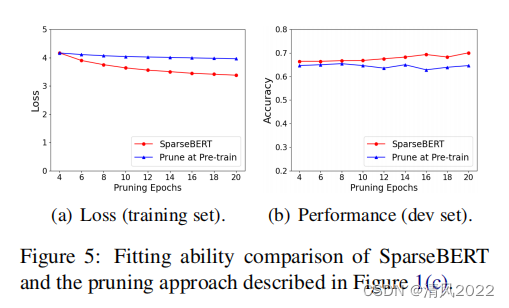
5 Discussion
5.1 Hardware Performance
稀疏网络在过去一致对硬件不友好。但是,硬件平台用得稀疏张量运算支持一直在兴起。为例如,最新发布的Nvidia高端GPU
A100具有稀疏张量运算的原生支持高达2倍的压缩率,而新兴公司如Moffett AI已经开发了计算平台,用稀疏张量运算加速可达到32倍的压缩率。
这里我们部署了不同的SparseBERT稀疏压缩比(1,2,4,8,16,20)Moffett AI最新硬件平台ANTOM来衡量真正的推理加速所引起的稀疏压缩,其中’ 4 '表示模型压缩了4倍,其中75%参数是0。如图6所示稀疏压缩几乎线性加速到4倍,当压缩率是20倍时可带来超过10倍的加速。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nWQ5GZbQ-1663228318989)(C:\Users\EDY\AppData\Roaming\Typora\typora-user-images\image-20220915153324540.png)]](https://img-blog.csdnimg.cn/df14e985c4204a208ead3eebe83a37be.png)
5.2 Reduction of Parameters and FLOPS
我们研究了参数和FLOPS的减少。例如,在MRPC数据集上,BERT-base(backbone)vs SparseBERT(backnone) = 85.53 vs4.84(#参数量,单位M)和BERT-base vs Sparse-BERT = 10.87 vs 0.54 (GFLOPS)。
5.3 推理/训练 时间
我们研究了时间和收敛速度。为例如,为了得到报告的20x剪枝结果(表1),需要在MRPC上进行12个epoch的微调,每个epoch耗时1.5 h(两个RTX 2080 Ti)。推理时间在20 s左右。
6 Conclusion
我们介绍SparseBERT,一个知识感知的预训练语言模型稀疏修剪方法,重点在BERT模型上。我们总结不同类型的BERT修剪方法和将SparseBERT和其他稀疏剪枝方法进行比较。在GLUE和SQuAD 上的实验结果证明了SparseBERT的优越性。








